Fraud often starts before a startup looks “big enough” to worry about it. I’d sum it up like this: rules catch obvious issues, but deep learning helps me spot patterns over time, linked accounts, and odd behavior that can slip past fixed limits.
If I were explaining the article in plain English, here’s the core message:
- Rules alone miss slow, split, and connected fraud
- Deep learning helps cut false alerts
- Three model types do most of the work:
- Anomaly detection for odd transactions and reporting mismatches
- Sequence models for step-by-step behavior shifts
- Graph models for account, device, and vendor links
- Small teams can use this well if data from banking, payroll, ledger, expenses, and tax systems is tied together first
- Good governance matters: model cards, drift checks, human review, and short reason codes for each alert
A few points stand out to me:
- Fraud can hide in repeated transfers just under $10,000
- False positives slow teams down and pile up review queues
- Linked-account risk often only shows up when I look at the network, not one record at a time
- Model outputs need to feed into finance work, audit trails, and board reporting - not sit in a dashboard no one uses
| Area | What deep learning helps find | What I’d do with the alert |
|---|---|---|
| Payments | Small repeated transfers, odd timing, behavior changes | Hold, review, or alert finance |
| AML/KYC | Linked entities, mule paths, shared devices | Start EDD review |
| Payroll/expenses | Outlier edits, approval gaps, odd reimbursements | Send to manual review |
| Reporting/tax | Record mismatches, disclosure gaps | Fix books and document follow-up |
Bottom line: if I want cleaner books, fewer missed fraud signals, and records I can defend in an audit, I’d use rules for hard policy breaches and deep learning for pattern-based risk.
Uncovering Financial Fraud with Graph Machine Learning at Scale
sbb-itb-17e8ec9
Where Rules-Based Monitoring Falls Short on Modern Fraud
Fixed thresholds can catch the obvious stuff. But they often miss fraud that stays just under the limit. Across payments, payroll, expenses, and reporting data, that gap gets used again and again. The three fraud patterns below show where deep learning starts to pull its weight.
Fixed thresholds miss small repeated transfers over time
Fraudsters often know exactly where the line sits. One common move is to split transfers into amounts just under $10,000 so they don't trip threshold-based monitoring. On their own, those transactions can look fine. Put them together across accounts and over time, and the pattern starts to look a lot different.
The same issue shows up in coordinated fraud. Fraud now moves through linked accounts and devices, so transaction-by-transaction rules miss what happens across the network. In AML and sanctions exposure, that blind spot can be costly. A chain of connected accounts can move funds across entities in ways that only show up when you look at the links between them, not just each record on its own. Rules treat every transaction like a separate event. Fraud usually doesn't work that way.
Manual review creates alert fatigue and case backlog
If you set thresholds wide enough to catch more fraud, you also catch a lot of normal activity. That fills the queue with false alerts and slows down review of the cases that matter. When analysts spend most of the day clearing false positives, real cases wait longer - and that lag is exactly what more advanced fraud schemes count on.
"Traditional rule-based fraud detection systems are increasingly inadequate in addressing the evolving and adaptive strategies employed by fraudsters." - Spiros Thivaios et al., Algorithms Journal
That's where pattern-based models help. They don't just ask, "Did this one transaction cross a line?" They ask, "What does this behavior look like over time?"
Deep learning adds pattern, sequence, and network detection
Instead of checking a single transaction against a fixed rule, neural networks look at sequences, relationships, and structural patterns across your full data set.
They can help in a few key ways:
- Sequence models spot behavior shifts over time, including small repeated transfers spread across a long run of normal-looking transactions.
- Graph models map links between accounts, devices, and merchants, which helps catch circular money flows or one account sending funds to many new recipients in a short period.
- Anomaly detection flags transactions that don't match the statistical profile of your business, even when they sit well below any fixed threshold. For startups, that can help surface suspicious activity before it turns into a filing or audit problem.
Use hard rules for plain violations. Use deep learning for fraud that changes shape and hides in patterns.
The next section shows how startups can apply these controls without a large compliance team.
Deep Learning Methods That Improve Fraud Detection and Compliance Results
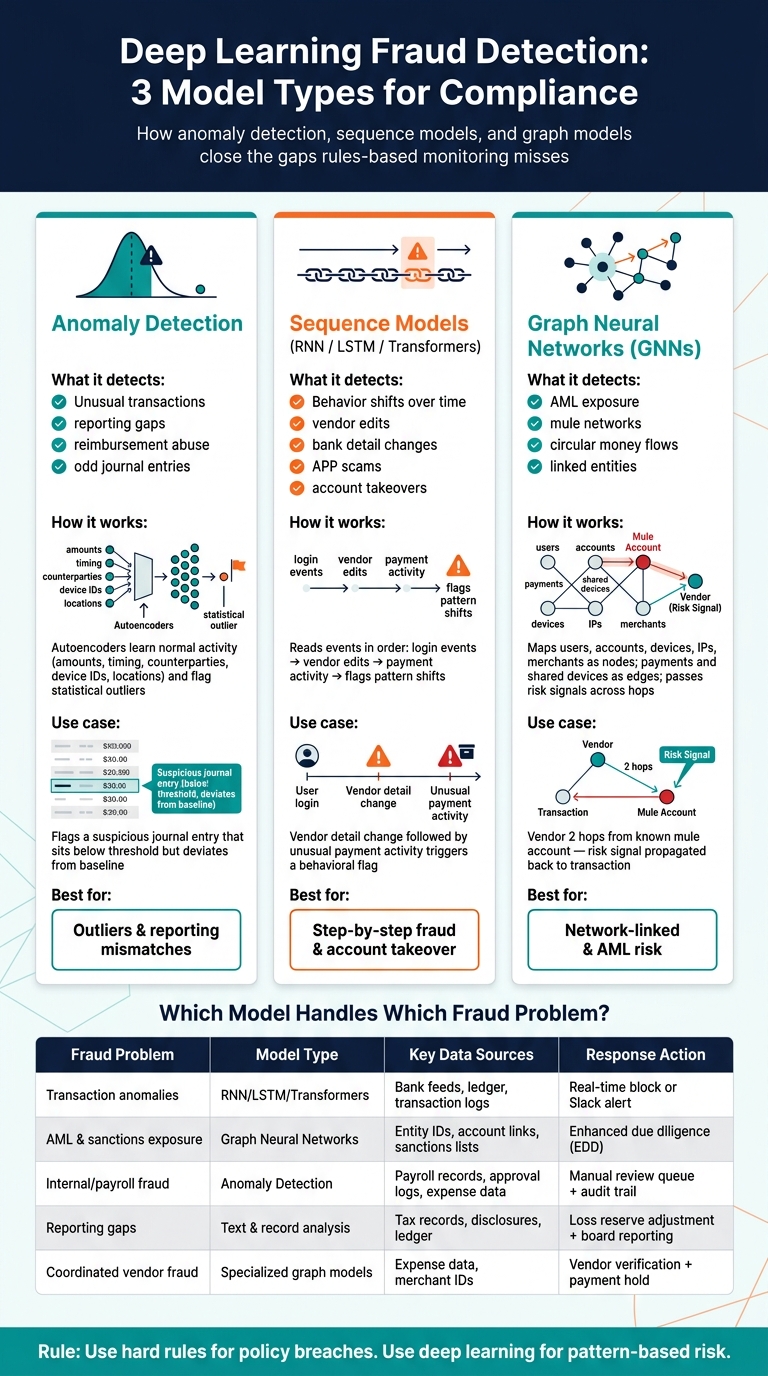
Deep Learning vs. Rules-Based Fraud Detection: A Compliance Comparison
Fixed thresholds and manual review can only take you so far. The gaps usually show up in places where activity looks normal on the surface but feels off once you add context. Three model families help close those gaps: anomaly detection, sequence models, and graph models.
Anomaly detection for unusual transactions and reporting gaps
Autoencoders learn what normal activity looks like based on transaction amounts, timing, counterparties, device IDs, and locations, then flag outliers. They don’t need labeled fraud examples to get started, which makes them useful when you’re trying to spot patterns that no rule covers yet.
For startups, that matters for internal controls and mismatches across records. Unusual journal entries, reimbursement abuse, and procurement irregularities often don’t look like obvious fraud. They just look slightly off from the baseline. When you link ledger, expense, and procurement records, you can spot inconsistencies that single-document checks often miss.
Sequence models add the time dimension.
Sequence models for detecting behavior changes over time
Sequence models read events in order and flag behavior shifts over time. Instead of judging one transaction by itself, they look at what happened before it: login events, vendor master file edits, bank detail changes, transaction streams, and tax filing workflow timestamps.
That time-based context helps with fraud that builds step by step. A vendor detail change followed by unusual payment activity may not trip any one rule. But a sequence model can still flag the pattern as a shift in behavior worth a closer look. This is especially useful for Authorized Push Payment (APP) scams and account takeovers, where each individual action looks legitimate, but the sequence gives it away.
Graph models add the relationship dimension.
Graph models for AML, mule networks, and linked entities
Graph Neural Networks (GNNs) treat each user, bank account, device, IP address, merchant, and counterparty as a node. Each interaction - a payment sent, a shared device, a reused address - becomes an edge connecting them.
That setup helps GNNs surface indirect risk. If a vendor or account sits two hops away from a known mule account, the GNN can pass that risk signal back to the transaction. For startups, one smart way to use this is to feed GNN outputs into a simpler decision model that’s easier to explain. That way, the compliance team can still trace and document why a flag was raised.
Use anomaly models for outliers, sequence models for behavior shifts, and graph models for network-linked risk.
The next step is turning those signals into controls a small team can actually run.
How Startups Can Apply Deep Learning Fraud Controls Without a Large Compliance Team
The goal is a lean operating setup where data, controls, and reporting turn fraud signals into action. After you pick the model type, the next step is simple: plug those signals into day-to-day finance work.
Unify ledger, bank, payroll, expense, and tax data first
Before any model can flag fraud, you need to connect bank feeds, ledger entries, payroll changes, expense logs, and tax data using matching timestamps and entity IDs. That groundwork matters more than people think.
A payroll adjustment with no approval record, or a vendor payment that doesn’t match a ledger entry, creates blind spots no algorithm can fix later. If that base layer is missing, deep learning doesn’t give you clarity. It gives you noise.
Use hybrid controls: hard rules for policy, models for patterns
Use hard rules for obvious policy breaches, like sanctions hits, blocked jurisdictions, and approval-limit violations. Save models for pattern-based risk.
That’s where models do their best work: unusual vendor payments, drifting expense patterns, and coordinated activity that looks normal on its own but suspicious when you look at the full picture. Every flag should go to a human review queue with a case note and a resolution step. That keeps the process grounded and gives you a record of what happened.
Connect fraud monitoring to cash flow, board reporting, and Lucid Financials workflows
Lucid Financials connects Slack alerts to bookkeeping, tax, and CFO workflows so fraud signals can update the books and board reporting fast.
The table below maps common fraud and compliance problems to the right model type, data source, and operating response:
| Fraud/Compliance Problem | Model Type | Primary Data Sources | Operational Response |
|---|---|---|---|
| Transaction anomalies | RNN / LSTM / Transformers | Bank feeds, ledger, transaction logs | Real-time block or Slack alert to the founder |
| AML & sanctions exposure | Graph Neural Networks (GNN) | Entity IDs, account links, sanctions lists | Enhanced due diligence (EDD) workflow |
| Internal/payroll fraud | Anomaly detection | Payroll records, approval logs, expense data | Manual review queue and audit trail update |
| Reporting gaps | Text and record analysis | Tax records, financial disclosures, ledger | Loss reserve adjustment and board reporting |
| Coordinated vendor fraud | Specialized graph models | Expense data, merchant IDs | Vendor verification, payment hold, Lucid Financials workflow |
The aim is fast action, accurate books, and audit-ready records. From there, document each model, watch for drift, and keep humans in the review loop.
Governance, Explainability, and Next Steps for Safe Compliance Use
Document models, monitor drift, and keep humans in the review loop
Once deep learning is live, governance is what makes it usable in a U.S. compliance review. If a model can't explain why it flagged something, it's tough to stand behind during an audit.
For documentation, keep a one-page model card that covers the model's purpose, data window, scope, thresholds, metrics, limits, and retraining cadence. Keep a dataset manifest too. It should log source systems, extraction time, and masking steps. And don't stop at a neat-sounding explanation. Check that the explanation lines up with what the model is actually doing, not just a plausible story. You can test that with sensitivity checks, surrogate fidelity, and counterfactuals.
After that, the next job is stability. Transaction behavior changes over time, and models can drift with it. Track precision and false-positive rates on a fixed cadence, then retrain when fraud patterns shift. Even a lean team can stay audit-ready by splitting work across execution, oversight, and independent review. You don't need a huge compliance department for that.
Turn model outputs into audit-ready explanations and next steps
To make alerts useful, turn model scores into short reason codes that reviewers can scan fast. Use a global summary to show model trends, and a local reason code for each alert, such as "Transaction velocity above baseline" or "New device detected." Those codes can flow straight into suspicious activity reviews, accounting follow-up, and board reporting.
A simple rule helps here: one owner, one control, and one artifact for each model stage. That keeps the process traceable and easier to defend.
FAQs
How much data do we need to start?
You don't just need a lot of data. You need high-quality data from your financial sources, like transaction records, vendor details, and employee data.
Before you use it, clean the dataset. Remove duplicates, fill in missing values, and standardize formats. Then split it into training, validation, and testing sets.
Lucid Financials helps bring together real-time data from your current tools for AI-powered compliance monitoring and fraud prevention.
What’s the difference between rules and deep learning?
Rules-based systems rely on fixed thresholds and manual reviews. That setup can work for simple cases, but fraud doesn’t sit still. As tactics shift, static rules can miss new schemes and flag more legitimate activity by mistake.
Deep learning takes a different path. It looks at large datasets to spot complex patterns and unusual behavior that rule-based systems may miss. In many cases, it’s better at finding sophisticated fraud.
There’s a catch, though. In the U.S., teams using deep learning often need extra controls to satisfy regulatory expectations around transparency and auditability.
How do we make model alerts audit-ready?
Make alerts explainable, defensible, and tied to clear data lineage. Each alert should show the exact data points and values that set it off, not just a feature importance chart.
Use explainable AI methods like SHAP to show transaction-level reasoning. Just as important, keep tamper-evident audit trails for inputs, decision logic, and reviewer rationale. Lucid Financials can help with real-time monitoring, version control, and audit-ready evidence binders.