ML can cut compliance review time, but it should only sort and flag work - not make the final call.
If I were a founder, I’d take away four things right away:
- Use ML as a triage layer. It can flag odd transactions, sort documents, rank alerts, and scan rule changes.
- Keep humans in charge. If a model changes a compliance outcome, a person should approve it.
- Bad data leads to bad reviews. Clean books, clean vendor records, and clear audit trails matter as much as the model.
- Watch the risk. Missed issues, alert overload, drift, bias, and weak logs can all turn into exam or audit trouble.
A few numbers make the point fast:
- Some teams use ML to handle up to 95% of recurring transactions while people review edge cases.
- In 2024, fintech penalties reached $4.2 billion.
- 73% of fintech startups delayed launches because of compliance bottlenecks.
In plain English: ML helps most with repeat work and large data sets. That includes transaction monitoring, document review, vendor checks, and rule tracking. But the model output has to be clear enough that I can explain why something was flagged and who approved the next step.
If I were rolling this out, I’d keep the plan simple:
- Start with one narrow use case.
- Test it on past data.
- Log inputs, outputs, versions, and approvals.
- Send low-confidence cases to a human.
- Track precision, recall, and review time.
The main idea is simple: use ML to speed up review, not to hand off accountability.
Always-On Compliance: How AI Creates a 24/7 View of Risk
sbb-itb-17e8ec9
How compliance models work in practice
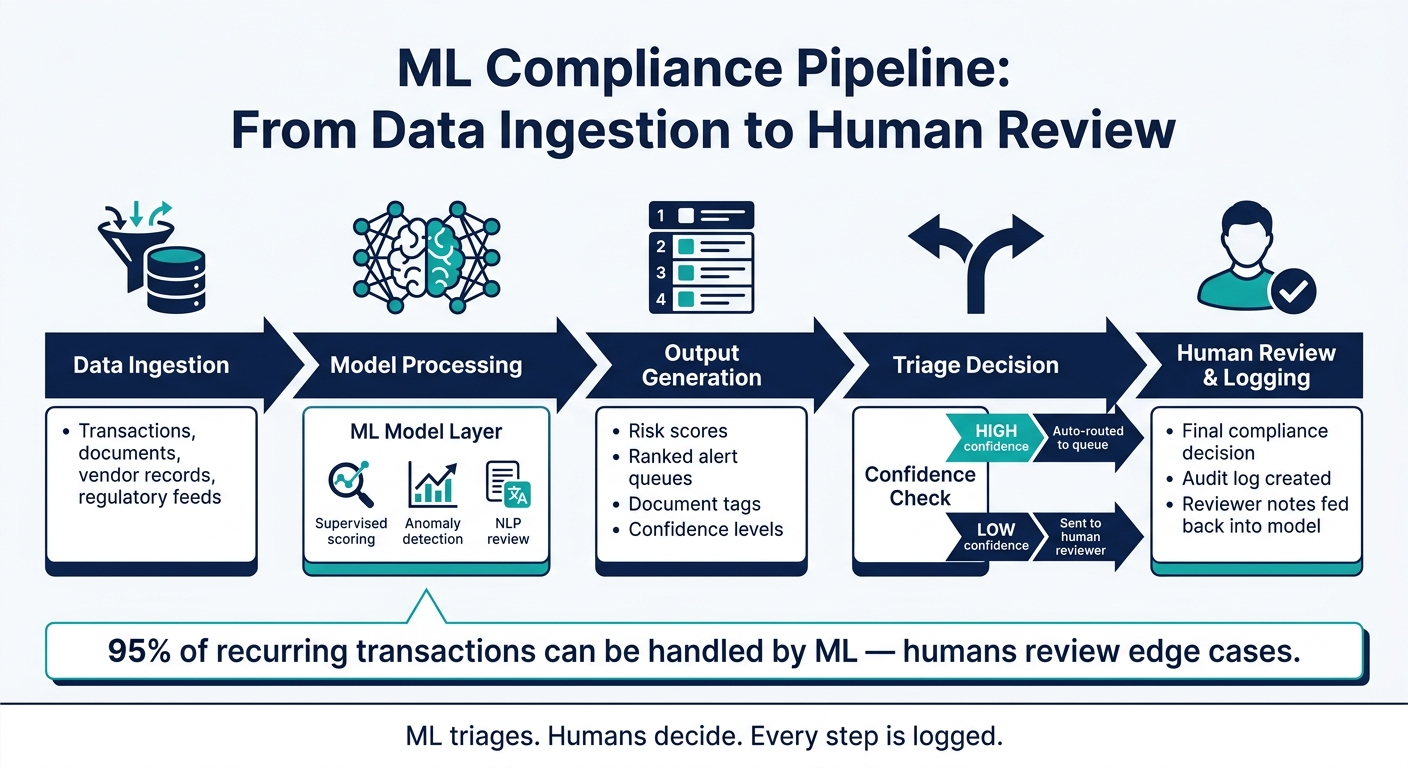
ML Compliance Pipeline: From Data Ingestion to Human Review
From data collection to human review: the basic pipeline
A compliance ML system usually follows three steps: ingest data, score risk, and send flagged items to human reviewers. You don't need a big, fancy setup on day one. You need a process you can repeat, from raw data to a review decision you can defend later.
Audit trails rely on clean data lineage, not only good predictions. If accounting records are messy or vendor data has gaps, even a strong model will spit out shaky results. Reviewer notes should flow back into the system too, so future scoring gets better over time.
That workflow shapes which model type makes sense for each compliance job.
The main model types used in compliance
Most compliance teams lean on three model types, and each one does a different kind of work.
Supervised learning is usually the best fit for risk scoring. It learns from labeled fraud cases, flagged transactions, or confirmed violations, then uses those patterns on new activity. It works best when you can clearly define what "risky" looks like from past examples.
Unsupervised anomaly detection builds a baseline of normal behavior and flags anything that falls outside it. That's especially helpful for spotting money laundering patterns or odd vendor activity that may never hit a fixed rule.
Natural language processing (NLP) handles the text-heavy side of compliance. Think contract review, policy scanning, entity-name matching across languages and alphabets, and tracking regulatory updates across jurisdictions.
What these models produce matters just as much as the way they work.
What useful model outputs look like
A compliance model only helps if its outputs make review faster. The outputs that matter most are risk scores, ranked alert queues, document tags, exception summaries, and confidence levels that show how sure the model is about a given flag.
The goal is a ranked alert queue that puts the highest-risk items at the top, with enough context to help someone make a fast call. That means gathered evidence and a short rationale, not a black-box score with no explanation. Log each step so you can explain decisions to auditors without scrambling.
These outputs matter most when you're using them for monitoring, document review, and regulatory tracking.
The startup use cases that matter most
The highest-value use cases are the ones that cut review time without weakening control quality.
Transaction monitoring and anomaly detection
For startups, one of the best places to use ML is where money moves.
A model can flag unusual spending patterns, duplicate vendor payments, reimbursements submitted twice, or transactions processed at odd hours. Those are the kinds of issues that are easy to miss in a spreadsheet but much easier for a system to spot. Its role is simple: shrink the review pile down to the highest-risk items.
The upside is faster visibility into exceptions and tighter control over burn. If out-of-policy transactions get flagged early, teams can catch issues before they pile up.
Document review, policy screening, and audit support
ML can also handle the classification work that slows audit prep down. It can sort invoices, tag contracts by type, and flag receipts with missing fields. That keeps audit evidence in order before deadlines show up.
But there’s a catch: this only works as well as your records do. Messy books lead to messy output, especially when accounts and vendor records don’t match.
Audit support only works when the underlying records are complete and traceable.
Tracking regulatory changes and vendor risk signals
Once internal workflows are covered, ML can help founders keep an eye on outside risk too.
Regulatory feeds can be monitored automatically, with updates summarized and tagged by business impact. That means your team can review what matters instead of scanning every update by hand. It also helps founders stay ahead of rule changes that affect policy updates, vendor review, or reporting duties.
Vendor risk follows the same pattern. Models can flag changes in third-party model lineage, data usage rights, sub-processor chains, and unsupported vendor claims before those issues turn into downstream exposure. Clean books and organized records make ML-driven review much more dependable.
The table below shows where ML helps and where people still make the call.
| Compliance Use Case | ML Role | Human Role |
|---|---|---|
| Transaction monitoring | Flags unusual spend, duplicates, and timing anomalies | Reviews and escalates alerts |
| Document review | Classifies invoices, contracts, and receipts; spots missing fields | Final sign-off on audit evidence packages |
| Regulatory tracking | Summarizes rule changes and tags them by business impact | Decides policy response and update priority |
| Vendor risk | Flags third-party model lineage, data usage rights, sub-processor chains, and unsupported vendor claims | Escalates and acts on high-risk signals |
Risks, governance, and rules founders need to track
Once ML starts triaging compliance work, governance becomes the line between speed and liability.
ML can move compliance review much faster. But if a team treats model output like a final answer, that’s where regulatory trouble starts. The main risks to track are missed issues, noisy alerts, model drift, bias, and outputs that reviewers can’t defend.
Model risks that create compliance problems
Start with the two most obvious failure points: missed issues and alert overload. A false negative means a real problem slips through with no flag. Too many false positives do the opposite - they burn review time and push teams toward uneven decisions. Then there’s model drift, which is easy to miss because it happens slowly. As customer behavior changes or criminal typologies shift, model performance gets worse unless you monitor it on a steady basis.
Bias is another serious problem. If the training data carries bias, the model can spread that bias at scale. The OCC now directly looks at AI-driven credit systems for disparate impact during fair lending examinations.
Unclear scoring also hurts your position in an audit. Regulators read "the AI decided" as the absence of a decision.
Brex's 2024 FINRA fine shows what this can cost. In that case, the firm relied on a poorly designed automated identity-verification model without enough controls.
The controls a compliant ML program needs
Those risks stay in check only when the workflow has firm guardrails.
ML can draft, score, and route cases. Humans should make the compliance decision. Any output that changes a compliance decision needs human sign-off. You also need a model inventory, access controls, logs, and version history. That paper trail is what examiners expect to see. Models should also go through independent review by someone who did not build the model.
In plain English, a compliant setup usually includes:
- Human approval for decision-changing outputs
- A full record of models, versions, access, and activity
- Independent validation and review
- Monitoring to catch drift, bias, and drops in performance
These controls line up with the rules founders are most likely to run into.
Key frameworks and standards to watch
Each framework below ties back to a founder decision - credit, broker-dealer activity, or EU operations.
| Framework | Scope | Risk Level | Documentation Burden | Operational Impact |
|---|---|---|---|---|
| Revised MRM Guidance | Complex quantitative models in banking; mainly applies at >$30B assets | Tiered by materiality | High - validation, monitoring, independent review | Independent review required for material models |
| NIST AI RMF 1.0 | Voluntary; all AI use cases | Variable | Moderate - risk profiles and model cards | Common vocabulary for AI-specific risks |
| SEC / FINRA Rules | Broker-dealers and investment advisers | Moderate | Moderate - logs of prompts, approvals, and distribution | Supervisory sign-off for AI-generated content |
| ECOA / Regulation B | Fair lending and credit decisions | High | High - explainability and adverse action reason codes | Requires bias testing and feature justification |
| EU AI Act | AI systems used with EU customers | High-risk for many financial use cases | Very high - technical documentation and ongoing monitoring | Human oversight and strict data governance for high-risk systems |
If you handle credit decisions or serve EU customers, start with the toughest rules first.
How to evaluate tools and roll out ML safely
What to look for in an AI-powered compliance tool
Once your controls are clear, the next step is simple: pick tools that make those controls easy to support. For a 10- to 100-person startup, that usually means choosing software that makes core compliance work easy to prove, repeat, and review.
Start with auditability. Every model-touched decision should leave behind a tamper-evident audit log with inputs, outputs, guardrails, and the identity of the person who approved it. If an auditor or examiner asks about a decision from months ago, you should be able to replay the full reasoning chain. If you can't, the log falls short. Right next to that is explainability. You want case-level explanations that show which factors led to a specific output.
On the security side, make sure the tool can de-identify nonpublic personal information (NPI) before any external API call. For integrations, watch SaaS logs and network traffic for unapproved AI use. This is where many teams get a wake-up call: most mid-market firms find between 30 and 80 AI tools already running when they do their first full sweep.
Also check for built-in human review workflows for high-risk outputs. If a tool can't cleanly hand off edge cases to a person, that's a problem waiting to happen.
A phased rollout from pilot to production
After you choose a tool, roll it out in stages. That's the safest way to test control quality before anything goes live. Start with one narrow use case and run it on historical data before using it in production.
A practical 90-day plan looks like this:
- Days 1–30: Build a draft inventory of every AI tool already in use and review SOC 2 reports for your top vendors.
- Days 31–60: Set up a one-page AI use policy and a vendor intake process with AI-specific questions built in.
- Days 61–90: Turn on continuous detection and run a tabletop exercise. Simulate a prompt leak or a data misroute so you can see where your escalation paths break down in practice.
Set a minimum factuality threshold, and send anything below it to human review. Then track the numbers that matter: precision, recall, SAR conversion rates, and time-to-disposition for flagged cases. Those metrics show whether the model is helping your team or just adding noise.
In-house builds also tend to become staffing-heavy within 18 months, which is why most startups do better with a fixed tooling budget.
That keeps ML in the right role: triage, not judgment.
Conclusion: What founders need to remember
Machine learning can improve compliance speed and signal detection in a meaningful way. One lending platform that put a three-layer AI compliance framework in place cut manual compliance work from 40 hours per week to 6 hours. That's a big gain. But it only lasts if the model runs on clean data, sits inside documented controls, and has a human owner for every material decision.
"Founders can use ML to improve judgment, not transfer accountability." - EverWorker
The rule is simple: use ML to speed review, not to transfer accountability.
FAQs
When is ML a good fit for compliance?
ML fits compliance best when teams need to automate manual, repetitive, or data-heavy work that tends to slow audits or make growth harder. It’s a strong option for continuous monitoring, real-time anomaly detection, and mapping internal controls to frameworks like SOC 2, ISO 27001, or GDPR.
It also helps when you need to review 100% of transactions instead of just 5%–10% audit samples, while keeping audit-ready, tamper-evident logs.
What data do I need before using ML?
Before you use machine learning, map out your systems, data flows, and AI use cases. That gives you a clear view of which rules apply and where risk might show up. Just as important, check your training data carefully: where it came from, how good it is, and what limits apply to how you can use it.
You’ll also want to pull together the core paperwork behind the work, including governance documents, accounting records, and contracts. From there, set up data governance policies that spell out who can access what, how privacy is protected, and how long data should be kept.
And don’t treat the model like a black box. You should know what goes in, how decisions are made, and which performance metrics tell you whether the model is doing its job.
How do I roll out compliance ML safely?
Start with governance, human oversight, and clear documentation. Make a clear inventory of your AI models and features. Then rank them by risk, and document their data sources and intended use.
Require human review of AI-generated outputs. Monitor performance, drift, and bias on a continuous basis. Keep immutable audit trails. Map regulatory requirements to operational controls, and assign a named owner to each one.