Small businesses face unique challenges when it comes to accessing credit. Limited financial histories and irregular data make it harder for lenders to assess their credit risk accurately. Traditional statistical models, like logistic regression, often fall short in identifying potential defaulters, with just 22% recall rates for small businesses. Machine learning offers a solution by analyzing alternative data sources, such as invoice payments and utility bills, to better predict creditworthiness.
Key takeaways:
- Logistic regression models achieve 79% accuracy but only identify 22% of defaulters.
- Machine learning models, like neural networks, reach 95% accuracy with a recall rate of 0.95.
- Alternative data (e.g., payment behavior) helps small businesses lacking detailed financial records.
- Implementing machine learning requires higher upfront costs but improves loan approval rates and reduces defaults.
Machine learning is reshaping credit risk assessment by addressing data gaps and improving prediction accuracy, especially for small businesses that lack extensive financial histories.
Advanced Data Science for Credit Risk Modeling: The Good, The Bad, and The Defaulted
sbb-itb-17e8ec9
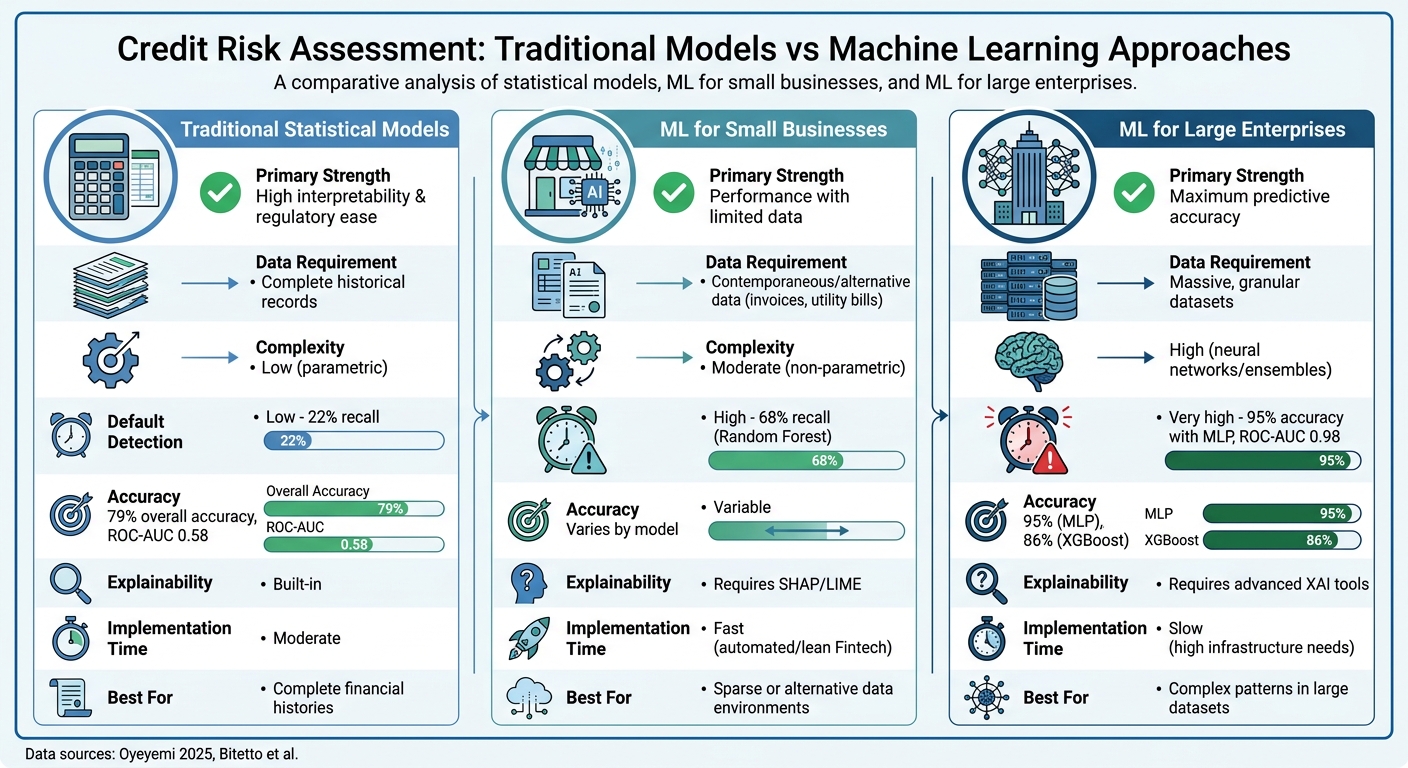
1. Traditional Statistical Models
Traditional statistical models, like logistic regression and ordered probit, have been the go-to tools for credit risk assessment for years. Their appeal lies in their straightforward design - each variable gets a coefficient that clearly shows its influence on the final credit score. This transparency makes them easy for lenders to understand and apply.
Data Requirements
These models depend heavily on "hard information", such as financial metrics like turnover, current liabilities, working capital, EBIT, and fixed assets, which are typically found in standardized financial reports. Large corporations usually provide this data through quarterly reports and audited statements. However, small businesses often lack detailed financial records, creating a significant challenge. Research by Gabriele Sabato and Edward I. Altman, which examined over 2,000 U.S. firms with sales under $65 million between 1994 and 2002, found that a small business-specific logit regression model could improve prediction accuracy by 30% compared to general corporate models. But this improvement relied on having complete financial ratio data - something many small businesses simply can’t provide. Without this data, the models struggle to forecast credit risk effectively.
Model Accuracy
While traditional models perform well with large datasets, they often falter when dealing with the complex, non-linear financial patterns typical of small businesses. For instance, a 2025 study by Deborah O. Oyeyemi at the University of Delaware showed that a logistic regression model achieved 79% overall accuracy but identified only 22% of actual defaulters. Its ROC-AUC score was just 0.58, highlighting its limitations.
"Traditional models such as logistic regression have long been the backbone of credit scoring because they are simple and interpretable. However, their ability to capture the complex and sometimes nonlinear nature of borrower behavior is limited, which often leads to misclassification of risk."
Additional research on 464 Italian small- and mid-sized businesses from 2015 to 2017 found that ordered probit models could match the performance of machine learning models - but only when complete financial statements and payment behavior data were available. Unfortunately, such comprehensive data is rarely available for small businesses, exposing a major weakness in these models.
Implementation Cost
Traditional statistical models are relatively inexpensive and easy to implement. They don’t require specialized hardware or heavy computational resources and can run on standard banking software. Plus, their results are simple to explain to regulators and stakeholders. However, there’s a hidden cost: their lack of precision. When a model can only identify 22% of defaulters, lenders face tough trade-offs. They may reject too many creditworthy borrowers or approve overly risky ones, leading to credit rationing for small businesses and missed opportunities.
2. Machine Learning for Small Businesses
Machine learning models are changing the game for small businesses, especially when it comes to credit scoring. Unlike traditional methods that rely on years of audited financial records, these models can evaluate credit risk using alternative data sources like invoice payment behavior, utility bills, or even employment history. This flexibility addresses the challenges small businesses face when they lack the extensive documentation required by older systems.
Data Requirements
One of the biggest hurdles for small businesses is the lack of detailed financial histories and formal records. Machine learning bridges this gap by incorporating alternative data, which is a lifesaver for cash-based or early-stage businesses that don’t have years of financial metrics to show.
For instance, fintech lenders have introduced invoice lending, where businesses use unpaid invoices as collateral for quick cash flow. Machine learning models analyze patterns like overdue payments or outstanding amounts, enabling faster and more precise lending decisions.
Model Accuracy
When it comes to accuracy, machine learning models significantly outperform traditional methods. For example:
- Multi-Layer Perceptron (MLP) neural networks hit 95% accuracy with a ROC-AUC of 0.98 for predicting small business credit risk.
- Logistic regression models, on the other hand, only managed 79% accuracy and a 0.58 ROC-AUC, correctly identifying just 22% of defaulters.
- Random Forest models bumped the defaulter recall to 68%.
- XGBoost models achieved 86% accuracy and a ROC-AUC of 0.74, though they sometimes leaned toward non-default predictions in unbalanced datasets.
These results highlight how machine learning not only improves accuracy but also reduces the risk of rejecting creditworthy applicants or approving risky loans.
Implementation Cost
While machine learning requires a larger upfront investment compared to traditional methods, the benefits often outweigh the costs. Setting up data platforms, real-time scoring systems, and tools like SHAP for explainable AI can be expensive. These tools are essential for ensuring fair lending practices and regulatory compliance, which adds to the initial expense. However, the payoff comes in the form of reduced manual underwriting time and a 20% performance boost in traditional scorecards.
For small businesses, this means quicker loan approvals and fewer denials due to incomplete documentation. And for lenders, identifying 68% of defaulters (compared to 22% with older methods) helps cut losses on bad loans while ensuring they don’t miss out on lending to reliable borrowers. These advancements set the stage for comparing how machine learning works in small businesses versus large enterprises, which we’ll explore next.
3. Machine Learning for Large Enterprises
When it comes to credit risk assessment, large enterprises operate in a completely different environment compared to small businesses. Instead of struggling with limited documentation, these companies benefit from a wealth of financial data, standardized reporting, and readily available market insights. They rely on what’s often called "hard information" - audited financial statements, stock market data, and long-term credit histories - all of which reduce the information gaps that complicate lending to smaller businesses.
Data Requirements
For large enterprises, standardized data sources like quarterly financial reports, SEC filings, and market performance metrics are the norm. Unlike small businesses that depend on alternative data, the challenge here isn’t collecting information but managing and processing enormous volumes of it. Some institutions now use models with trillions of parameters - akin to GPT-4 - which brings unique hurdles such as high computational costs and concerns about data privacy when external APIs are involved. While this standardized data offers an advantage, it also introduces complexities in ensuring accuracy and scalability.
Model Accuracy
Traditional models work well with complete historical data, but integrating both structured and unstructured data can take accuracy to the next level. Modern credit risk assessments increasingly rely on multimodal data fusion - combining structured financial data with unstructured inputs like annual report text and news sentiment. For instance, a multimodal LLM-LoRA framework achieved an F1 score of 0.829, marking a 50.3% improvement over models using only financial data. Adding non-financial data can further enhance model accuracy by 8.5% and improve goodness-of-fit by 12.3%. However, managing these improvements at scale requires advanced solutions.
Scalability
Scalability is a unique challenge for large enterprises. Instead of dealing with sparse data, they must handle massive parameter counts and significant computing demands. Techniques like Low-Rank Adaptation (LoRA) help reduce computing costs while maintaining accuracy. Yet, general-purpose models like GPT-4 can struggle with "knowledge dilution", where they fail to capture the specific nuances of credit risk assessment.
Implementation Cost
The financial commitment required for large-scale machine learning models is substantial. Models with trillions of parameters demand immense computing resources, both for training and deployment. Enterprises often face a tough decision: rely on third-party APIs (which could risk the privacy of sensitive credit data) or invest heavily in local infrastructure. Additionally, regulatory requirements for transparency mean companies must use tools like SHAP and LIME to ensure their models meet explainability standards. All of this contributes to significantly higher infrastructure costs for large enterprises.
Pros and Cons
Machine Learning vs Traditional Models for Small Business Credit Risk Assessment
Each credit risk approach brings its own strengths and challenges to the table. Traditional statistical models, such as logistic regression, are praised for their interpretability and ease of meeting regulatory requirements. These models are often considered the "backbone" of credit scoring. They work well when lenders have access to complete historical financial data. However, they fall short when dealing with non-linear patterns or imbalanced datasets, limiting their ability to accurately identify defaulters. These shortcomings have opened the door for machine learning (ML) models to step in.
Machine learning for small businesses shines in situations with sparse or alternative data. For instance, Random Forest models have demonstrated the ability to boost defaulter recall rates to 68%. This makes ML particularly useful for Fintech platforms, which often operate in data-limited environments. However, these models require tools like SHAP or LIME to meet regulatory explainability standards. Alessandro Bitetto from the Department of Economics and Management highlights this advantage:
"Machine learning techniques overperform traditional techniques, such as probit, when the set of information available to lenders is limited".
Machine learning for large enterprises delivers unmatched predictive accuracy. These models can uncover intricate patterns in massive datasets, but they demand significant computational resources. For example, while XGBoost performs well overall, it has shown bias toward non-default cases in unbalanced datasets. The choice of model ultimately hinges on the balance between data availability and the technological resources at hand.
The decision on which approach to use depends largely on the data environment and available resources. Traditional models are ideal when historical financial records are complete and transparent results are a priority. ML approaches for small businesses are better suited for environments with limited or alternative data, while ML for large enterprises excels in capturing complex patterns but requires heavy investment in technology and expertise. This comparison highlights how the data environment and infrastructure shape credit risk strategies.
| Criteria | Traditional Statistical Models | ML for Small Businesses | ML for Large Enterprises |
|---|---|---|---|
| Primary Strength | High interpretability & regulatory ease | Performance with limited data | Maximum predictive accuracy |
| Data Requirement | Complete historical records | Contemporaneous/alternative data | Massive, granular datasets |
| Complexity | Low (parametric) | Moderate (non-parametric) | High (neural networks/ensembles) |
| Default Detection | Low (22% recall) | High (68% recall) | Very high (95% with MLP) |
| Explainability | Built-in | Requires SHAP/LIME | Requires advanced XAI tools |
| Implementation Time | Moderate | Fast (automated/lean Fintech) | Slow (high infrastructure needs) |
Conclusion
Machine learning addresses credit risk challenges that traditional models struggle to solve. When data is sparse, irregular, or lacks historical depth - a scenario many small and medium-sized businesses (SMBs) face - methods like ensemble tree-based models (such as Random Forest, XGBoost, and AdaBoost) consistently outperform older approaches. These advanced techniques uncover patterns that traditional models often miss, turning limited data into opportunities for better credit access.
For businesses with incomplete financial records, focusing on behavioral data is critical. Metrics like invoice payment history, bank transaction flows, and recent financial snapshots provide reliable, actionable signals for accurate predictions. As Jay Richardson, SVP & General Manager at Uptiq, explains:
"AI-driven credit scoring has the power to unlock SME credit, drive inclusion, and reduce risk, all at scale".
This shift in focus requires rethinking both model design and data strategies. Ensemble methods, combined with explainability tools, strike a balance between performance and transparency. Models like Random Forest and Gradient Boosting not only deliver strong predictive results but, when paired with tools like SHAP or LIME, also provide insights into decision-making. This combination reduces underwriting times from days to minutes while ensuring compliance and fairness.
Small businesses should pay close attention to financial drivers such as turnover, current liabilities, working capital, and EBIT. Additionally, invoice-specific indicators like delinquency rates and outstanding balances play a critical role. By understanding how these variables impact credit ratings, business owners can take proactive steps to improve their borrowing position and secure better loan terms.
These advancements pave the way for a more equitable credit system, one that evaluates businesses based on their current financial health rather than penalizing them for a lack of credit history. Machine learning not only improves accuracy and recall but also speeds up approvals and promotes fairer risk assessments.
At Lucid Financials, we’re dedicated to using these insights to empower SMBs, enabling smarter and more inclusive financial decisions.
FAQs
What alternative data can lenders use for small business credit scoring?
Lenders have the opportunity to improve small business credit scoring by incorporating alternative data, which is especially valuable for businesses with limited credit histories. This data can come from various sources, including demographic, financial, employment, and behavioral information. Examples include education level, marital status, income, and job tenure.
Additionally, data like invoice records, industry-specific trends, and broader behavioral patterns can play a key role. These inputs help machine learning models deliver more accurate results, paving the way for lending practices that can reach a wider range of businesses.
How do lenders handle fairness and explainability with ML credit models?
Lenders work to maintain transparency and accountability in machine learning (ML) credit models by employing tools like interpretability analysis - SHAP values, for instance - to reveal how different features impact predictions. They also use fairness-focused modeling approaches to address and minimize biases, especially when dealing with businesses that have historically been underserved. By blending traditional credit scoring methods with AI-driven tools, lenders enhance clarity in decision-making. At the same time, advanced techniques for interpretation and bias reduction help build trust and promote responsible practices in credit evaluation.
What data should I track to improve my business’s loan approval odds?
To improve your chances of securing a loan, keep a close eye on important financial metrics such as cash flow, revenue, expenses, and your debt service coverage ratio (DSCR) - most lenders look for a DSCR of at least 1.25. Additionally, pay attention to factors like your payment history, total amounts owed, the length of your credit history, and even alternative data, such as patterns in digital transactions. Tools like Lucid Financials can simplify this process by compiling these metrics into real-time, actionable reports, giving you a clearer view of your financial health.


