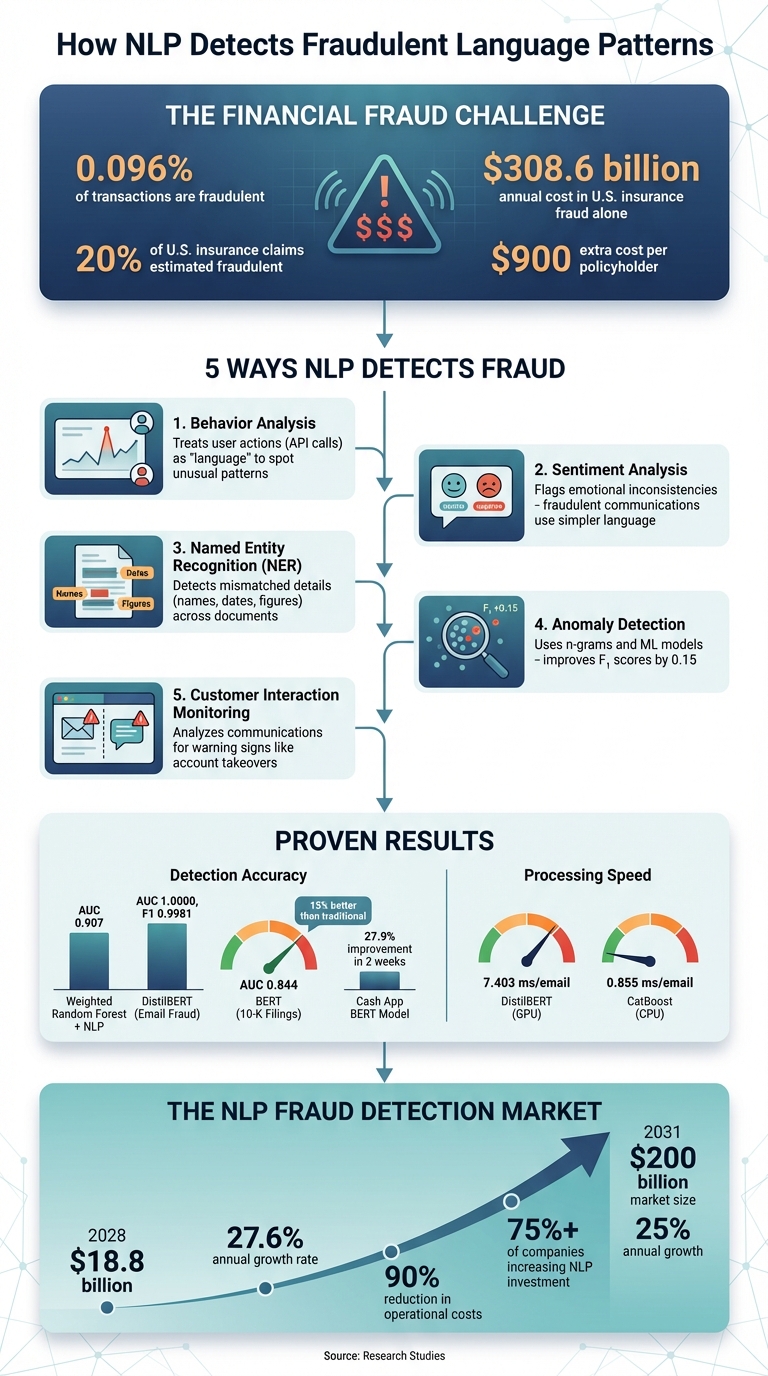
NLP (Natural Language Processing) is transforming how financial fraud is detected. By analyzing user behavior and unstructured data like emails and transaction logs, NLP identifies patterns and anomalies that traditional systems often miss. Fraudulent activity is rare - about 0.096% of transactions - but its impact is massive, costing billions annually in sectors like insurance and banking.
Here’s how NLP helps:
- Behavior Analysis: Treats user actions (e.g., API calls) as "language" to spot unusual patterns.
- Sentiment Analysis: Flags emotional inconsistencies in communications, like overly simple or aggressive language.
- Named Entity Recognition (NER): Detects mismatched details (e.g., names, dates) across documents.
- Anomaly Detection: Uses tools like n-grams and machine learning models to find irregular activity sequences.
- Customer Interaction Monitoring: Analyzes chat logs and emails for warning signs of fraud, such as account takeovers.
NLP systems are faster, scalable, and more precise than manual reviews, making them essential for startups and financial institutions managing high transaction volumes. As fraud tactics evolve, these tools continue to improve detection accuracy by analyzing both structured and unstructured data sources.
How NLP Detects Fraud: 5 Key Techniques and Performance Metrics
AI Powered Fraud Detection for Payments & Transactions | Maimoon Saleem | DSC MENA 25
NLP Techniques for Detecting Fraudulent Language Patterns
Advanced NLP techniques take fraud detection to the next level by analyzing language patterns within large volumes of unstructured data, such as emails and contracts. These methods help uncover deceptive behaviors that might otherwise go unnoticed.
Sentiment Analysis
Sentiment analysis examines the emotional tone in financial communications to identify potential red flags. By analyzing tone, sentiment, and structure across channels like phone calls, emails, or chat messages, this technique can reveal inconsistencies or overconfidence in claim narratives. For instance, mismatched emotional cues - such as undue distress or aggression during high-value transactions - can signal fraudulent intent. Interestingly, fraudulent communications often feature simpler language, with fewer complex words.
As Adarsh Gowda, a data science expert, explains:
"Through the identified textual features, NLP proves to advance the previous sign of intent detection by such a marginal level that a human-compiled checklist would overlook."
Sentiment analysis also helps flag vague refund requests or suspicious transaction details, offering a layer of detection that traditional methods might miss. This proactive approach can identify deceptive patterns early, reducing the risk of financial losses.
Named Entity Recognition (NER)
NER focuses on identifying and categorizing key elements like names, dates, and figures within documents. It flags inconsistencies by comparing these entities across different records. For example, if injury details in a claim form differ from those in a medical report, NER can highlight the discrepancy. Additionally, it maps relationships between entities in seemingly unrelated claims, uncovering hidden connections.
NER is particularly effective in temporal analysis, detecting anomalies in event sequences or timelines. This is critical, given that around 20% of insurance claims in the U.S. are estimated to be fraudulent, costing approximately $308.6 billion annually - or about $900 per policyholder. By automating the verification and cross-referencing of entities, NER reduces the manual workload involved in exposing sophisticated fraud schemes.
Anomaly and Pattern Detection
NLP methods like n-gram analysis and TF-IDF can treat financial transactions and online banking actions as sequences, much like natural language. These techniques identify suspicious patterns, such as anomalous unigrams, bigrams, or trigrams. Certain sequences are more common in fraudulent activity than in legitimate transactions, and integrating these features into models like Random Forest can improve F₁ scores by up to 0.15 compared to traditional features.
Unsupervised algorithms, including Isolation Forest, k-NN, and LOF, are also used to calculate normality scores. For example, shorter Isolation Forest paths often indicate anomalies. Additionally, topic modeling builds knowledge-based ontologies to categorize and detect fraudulent patterns in unstructured financial documents. These advanced pattern detection tools provide real-time insights into emerging fraud tactics, strengthening financial compliance systems against evolving threats.
Applications in Financial Compliance
Financial institutions are now leveraging advanced NLP techniques to transform compliance monitoring. By analyzing unstructured data - like transaction details, emails, and chat logs - NLP opens up new possibilities that traditional systems often miss. The financial NLP market is expected to hit $18.8 billion by 2028, with a compound annual growth rate of 27.6%. This rapid growth reflects how NLP can cut operational costs by as much as 90% while identifying fraud that might otherwise go unnoticed in numerical data.
Transaction Monitoring
Transaction monitoring is one of the standout areas where NLP is making a difference. Instead of just flagging individual transactions, modern NLP systems evaluate the entire sequence of actions within a transaction process. For instance, these systems analyze activities like logging in, checking balances, fetching cards, and making payments to detect unusual patterns. A sudden uptick in /card/fetchcards API calls, for example, could signal suspicious behavior and potential fraud.
NLP also examines transaction descriptions, looking for linguistic red flags such as coded language (e.g., "PCHSOPRS121"), overly simple phrasing, or abrupt shifts in language style.
To monitor transactions effectively, financial institutions typically use two approaches:
- Real-time monitoring: Focuses on precision to reduce false positives during live transactions, often using F₀.₅ scores.
- Offline historical audits: Prioritizes recall, using F₂ scores to uncover violations that might have been missed earlier.
Additionally, Natural Language Generation tools can produce detailed fraud alert explanations, helping investigators understand why specific transactions were flagged.
Customer Communication Screening
NLP extends beyond transactions, playing a critical role in analyzing customer interactions. By examining phone calls, emails, and chat logs, NLP systems can detect changes in customer behavior that might signal fraud, such as account takeovers. These tools enable real-time, automated analysis of customer interactions.
For instance, in July 2024, Cash App implemented a fine-tuned BERT model to analyze free-form text from customers reporting unauthorized transactions. This model, trained to identify language patterns linked to account takeovers, achieved a 27.9% improvement in the Area Under the Precision-Recall Curve over two weeks, outperforming basic keyword matching, which showed a 12.3% improvement.
NLP techniques like Named Entity Recognition (NER) are also invaluable. NER extracts key details - names, dates, locations, and financial figures - from customer communications, cross-referencing this information with regulatory watchlists and fraud databases. Chatbots equipped with NLP can even flag suspicious language in real time, alerting human reviewers before fraudulent transactions occur. Notably, more than 75% of companies involved in NLP projects plan to increase their investment in these technologies within the next 12 to 18 months.
At Lucid Financials, we incorporate these advanced NLP tools to strengthen compliance for startups and fast-growing businesses. This ensures robust fraud detection and smooth customer communication monitoring in real time.
sbb-itb-17e8ec9
Research Findings and Performance Metrics
Research Studies
Recent studies highlight how NLP-based fraud detection methods surpass traditional approaches. One notable example comes from Aoyama Gakuin University, where researchers examined the Management's Discussion and Analysis (MD&A) sections of Japanese listed companies between 2010 and 2019. They used a Weighted Random Forest model combined with NLP techniques to analyze linguistic variables like negative tone, complexity, and a reduced use of ratio-based expressions. This approach achieved an impressive AUC of 0.907. Kenichi Yazawa and his team observed:
leveraging textual data provides an effective new approach to predicting financial fraud and has the potential to contribute to corporate fraud prevention.
Another study focused on the FraudNLP dataset, which included 105,303 transactions from 2,000 users at a European bank. By treating API call sequences - such as login attempts, balance checks, and payments - as language patterns, researchers improved the F₁ score of Random Forest classifiers by 0.15 compared to traditional Recency, Frequency, Monetary (RFM) methods. In the realm of Business Email Compromise detection, the DistilBERT model achieved near-perfect results, with an AUC of 1.0000 and an F1-score of 0.9981. Similarly, BERT-based models analyzing 10-K filings outperformed traditional methods by about 15%, with the BERTfirst model maintaining an average AUC of 0.844 across test years from 2014 to 2021.
These findings emphasize the effectiveness of NLP in fraud detection, particularly when paired with its speed and ability to scale.
Performance Comparisons
NLP systems not only excel in detection accuracy but also deliver unmatched processing speeds and the capacity to analyze vast datasets. For instance, the DistilBERT model processes emails at 7.403 milliseconds per email on a GPU, while the CatBoost model is even faster, handling emails at 0.855 milliseconds per email on a CPU. Given the sheer volume of daily transactions, manual review becomes impractical. According to Springer Nature, automated systems act as a critical safeguard before human intervention.
These models also excel at identifying fraud hidden in extensive text. For example, fraudulent 10-K filings average 12,482 words, significantly longer than the 8,926-word average of legitimate filings. This suggests that fraudsters may intentionally use lengthy documents to obscure their activities. NLP models can analyze these sizable datasets automatically, adapting to evolving fraud patterns with minimal setup.
Future Directions in NLP Fraud Detection
Multimodal Analysis
The future of fraud detection lies in combining multiple data types - text, images, audio, transaction logs, and behavioral patterns - to uncover fraud that single-mode systems might miss. For instance, a banking system could analyze chat logs alongside transaction histories to detect social engineering attempts that a text-only approach might overlook. Imagine a scenario where a customer service call originates from a foreign IP address. By cross-referencing voice biometrics with the user’s usual device patterns and geolocation, the system can differentiate between a legitimate traveler and a potential fraudster.
Through cross-modal attention, these systems link different data types. For example, they might match transaction timestamps with app usage habits or compare a live selfie with ID scans to validate anomalies in real time. This layered verification process reduces false positives by confirming legitimate irregularities through multiple channels rather than flagging every unusual activity. Such a cross-channel strategy also supports fraud detection in multilingual contexts.
Cross-Lingual Fraud Detection
Fraud detection systems must also address language diversity. Fraudsters operate across linguistic boundaries, and detection tools need to do the same. Research is now expanding beyond English to include underrepresented languages like Bangla, spoken by over 250 million people. A 2026 study on Bangla-English fraud highlighted that scam messages often included URLs and phone numbers, while legitimate messages were typically shorter and referenced specific currencies. The study found that Linear SVM models achieved 91.59% accuracy and a 91.30% F1 score when analyzing code-mixed messages, where fraudsters alternated between languages. Interestingly, while classical machine learning models outperformed transformer models in overall accuracy (91.59% vs. 89.49%), transformers excelled in fraud recall, achieving 94.19%. These findings underscore the importance of tailoring fraud detection tools to diverse linguistic and communication styles.
Emotion AI and Behavioral Modeling
Emotion AI adds another layer of sophistication by identifying subtle emotional cues - like distancing or abrupt tone changes - that could signal fraudulent intent. Faheem Shakeel, Practice Head at Damco Solutions, notes that sentiment analysis can help distinguish legitimate submissions from fraudulent ones.
The financial stakes are enormous. In the U.S. alone, insurance fraud costs around $308.6 billion annually, translating to an extra $900 per policyholder. Behavioral modeling further enhances detection by tracking shifts in customer behavior, such as becoming argumentative or evasive when asked to verify details. Temporal analysis of claim narratives can also flag inconsistencies that might escape human reviewers. These advancements complement traditional NLP methods, making fraud detection more precise. With the NLP market expected to grow at a 25% annual rate, reaching $200 billion by 2031, tools like emotion AI and behavioral modeling are set to play a key role in identifying fraud signals that older methods might miss.
Conclusion
For startups and fast-growing companies, financial fraud isn't just a compliance headache - it’s a threat to their survival. In the U.S. alone, insurance fraud racks up a staggering $308.6 billion in losses each year. Traditional fraud detection systems, which often focus solely on transaction amounts, fail to catch the intricate schemes fraudsters craft. As Faheem Shakeel, Practice Head at Damco Solutions, aptly notes:
Behind every false claim is a carefully crafted narrative to deceive insurance companies.
This is where Natural Language Processing (NLP) steps in as a game-changer. By analyzing unstructured data - like emails, chat logs, and even social media - NLP identifies patterns and anomalies that would be impossible for human teams to process at scale. Beyond just spotting irregularities, it digs deeper, uncovering intent through sentiment analysis, linguistic inconsistencies, and emotional cues - key indicators of deceptive behavior.
NLP’s real-time monitoring capabilities can intercept fraudulent activities before they spiral out of control. Automation further enhances efficiency, allowing analysts to concentrate on more complex cases. For rapidly expanding companies, this scalability is crucial. With the global NLP market expected to surpass $200 billion by 2031, growing at a 25% annual rate, it’s clear that these systems are becoming foundational.
This technology also paves the way for a broader transformation in fraud detection strategies. Companies must move beyond rigid, rule-based systems and embrace adaptive NLP-driven platforms that evolve alongside fraud tactics. This means incorporating unstructured data into fraud detection workflows, regularly updating models to recognize new linguistic patterns, and cross-referencing flagged entities with watchlists to create a stronger, more secure system.
At Lucid Financials, we use NLP to provide real-time insights and robust fraud detection, helping startups safeguard their financial operations in today’s high-speed business environment. By doing so, we empower them to stay ahead of threats and focus on growth.
FAQs
What data sources does NLP use to detect fraud?
Natural Language Processing (NLP) plays a key role in spotting fraud by examining linguistic clues. It looks at things like word frequencies, unusual phrases, language irregularities, and specific features such as sentiment, readability, and named entities. By analyzing financial documents, reports, and filings, NLP uncovers patterns that may signal fraudulent behavior.
How do you reduce false positives in NLP fraud alerts?
To minimize false positives in NLP-based fraud detection, strategies such as alert prioritization and risk scoring come into play. These approaches are designed to distinguish actual threats from harmless language patterns, leading to more precise detection and a significant reduction in unnecessary alerts.
How often should fraud NLP models be retrained?
Fraud detection NLP models need regular retraining to stay effective. Language patterns and fraud tactics evolve over time, so keeping models updated ensures they can accurately identify potential threats. Experts suggest retraining these models every few months or whenever there’s a significant influx of new data to keep their performance sharp.


